Every few months one AI model swallows the industry's attention, and for the early part of 2026 that model is Seedance 2.0. It has been praised for cinematic video, for sound baked into the same clip, for camera work that looks planned by a human and for characters that stay consistent across a scene. My feeds on X, YouTube, Reddit and LinkedIn filled with it inside a week.
The obvious question is why this one, out of the dozens of video generators that launch every year.
I went through the official ByteDance material, the independent blind-vote benchmarks, the pricing pages of the platforms that host the model, and the coverage of what happened after launch. Two forces explain the noise, and they pull in opposite directions. One is genuine capability. The other is a run of drama that would have pushed almost any model into the feed.
This is an analysis of both, not a highlight reel. Where a claim comes from ByteDance I will say so, and where it comes from independent testing or reporting I will say that too.
Why is everyone talking about Seedance 2.0?
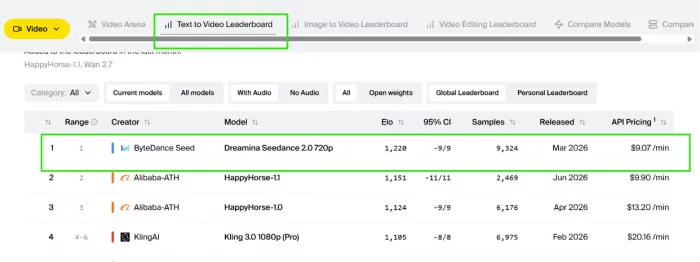
- It generates video and matching sound in a single pass, and it leads the audio categories on the Artificial Analysis blind-vote leaderboard
- Its clips hold one character and one setting across multiple shots, which older models struggled to do
- It went viral on hyper-real clips of famous faces, which pulled in a mainstream audience fast
- That same virality drew legal pressure from major studios and a paused global rollout, which kept it in the headlines
- It comes from ByteDance, the company behind TikTok, so distribution and research muscle were never in question
On this page: A quick map of the AI video race · What Seedance 2.0 actually is · Why it took over the conversation · The drama that turned attention into noise · How it stacks up against the field · Is the hype justified? · Who gets the most out of it · The limits worth knowing · Where this leaves AI video
AI media moved from still images to short clips faster than most people expected. Two years ago a coherent five-second shot was a novelty. Now several models produce clips with sound, camera motion, consistent characters and physics that mostly behaves, and the competition among them is fierce.
The field going into 2026 had a clear shape. Google's Veo pushed synchronized dialogue. Kling shipped reliable high-resolution clips. Runway held the richest control tools for editors. OpenAI's Sora had the biggest name. Then two things happened close together. ByteDance released Seedance 2.0 in February and it went straight to the top of the sound-enabled leaderboards, and weeks later OpenAI shut Sora down.
So part of the reason Seedance dominates the conversation is blunt. One of its loudest rivals stopped existing, and Seedance filled the space.
One shift explains why a new model can still make waves. Resolution stopped being the differentiator. Every serious system now reaches 1080p or higher, so sharpness alone no longer wins a comparison. The contest moved to harder ground: sound, motion that obeys physics, control precise enough for a deadline and characters that survive a cut. Seedance planted its flag on the first of those and made a credible claim on the rest.
Creators want realism because realism is what makes AI video usable for paying work. A clip that needs less fixing is a clip that ships. The stakes are commercial. A studio that can previsualize a scene in an afternoon, or a brand that can test ten ad hooks before lunch, saves real budget, and that is the audience these tools chase. Seedance arrived promising exactly that, and the early benchmarks backed enough of the promise to make people look. Where it fits is at the front of the audio-native tier, which the next section unpacks.
Seedance 2.0 is a video generation model from ByteDance's SEED research lab, released on 12 February 2026. It takes text, images, video and audio as inputs and produces short clips with native sound. The pitch is a single tool that goes from a written idea to a finished shot with dialogue and music already in place.
The headline capability is its input system. One generation can take up to twelve references, each tagged with an @ symbol so it has a defined job. You can hand it an image for a character, a clip for a camera move, an audio track for rhythm and a frame for lighting, and the model weaves them together.
That tagging is what separates this from a plain text prompt. A prompt describes; a tag points. Handing the model an actual reference and assigning its role removes the guesswork that makes text-only generation drift.
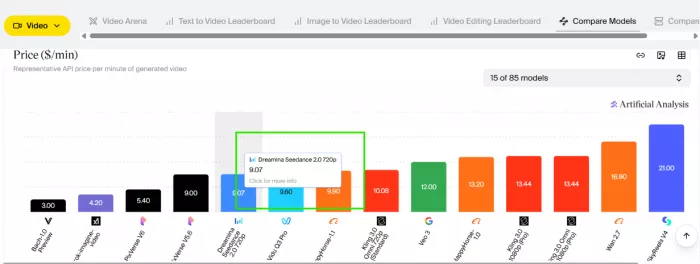
Clips run up to fifteen seconds. Free and base tiers output 720p, with 1080p and 2K reserved for higher tiers.
The model ships in more than one flavour. A Standard tier aims for final quality, while a Fast tier trades some fidelity for speed on early passes. It also covers six aspect ratios and supports video-to-video editing, so an existing clip can be restyled or extended instead of built from scratch.
The intended users are broad. It targets content creators making short social video, marketers building ad drafts, filmmakers storyboarding scenes before a shoot and small studios testing concepts. What it does not offer is custom fine-tuning of a model, so a fixed brand character has to be rebuilt from references each time.

Strip away the noise and a handful of capabilities did the real convincing. These are the ones creators kept pointing at.
The audio problem it solved first
For years, AI video and AI audio were separate steps. You generated a silent clip, then generated or recorded sound, then lined them up by hand. Seedance 2.0 collapses that into one pass. The clip arrives with dialogue, lip movement, a background score and ambient effects already synced to the picture.
To see why that matters, look at the workflow it removes. A silent clip normally needs a separate voice track, sound effects layered in by hand, a music bed and a sync pass to line it all up. Seedance folds those jobs into the generation, so a usable draft exists before any editing starts.
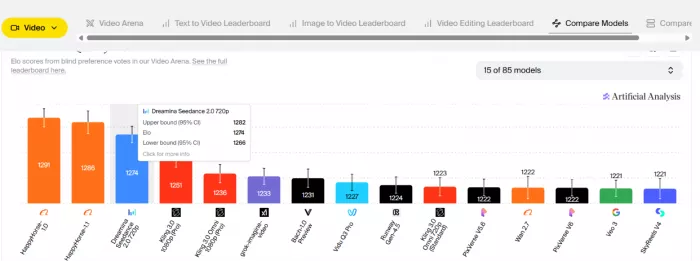
This is why it sits first in the sound-enabled categories of the Artificial Analysis Video Arena, a leaderboard scored by blind human preference rather than by the vendor.
The caveat that rarely makes the demos: the dialogue is tuned for English. Other languages work, but timing and lip sync on them are less dependable. For a global campaign that gap matters.
The second draw is visual. In its strongest examples the lighting, texture, surface detail and depth read as filmed rather than rendered. The materials and the motion carry a filmed feel that earlier models missed, which is a large part of why the clips screenshot well and spread.
Camera control is part of the appeal too, though it is oversold. The model responds to described moves like pans and orbits, but the control is mostly through prompt wording, and fine pacing is coarse. A small change to a prompt can swing the framing hard. The cinematic look is real, and the precision behind it is looser than the marketing suggests.
Multi-shot storytelling is the feature that makes this matter for ads and short films, because a hook and a payoff can live in one clip instead of four stitched together.
Consistency is less flashy than audio, and for commercial work it may matter more. A recurring character, a brand mascot, a product or a spokesperson has to look the same from shot to shot, or the piece falls apart. Older models drifted, morphing a face or an object between frames. Seedance holds identity across a scene from a reference image, which is what lets one generation read as a single coherent sequence rather than a set of loosely related clips.
The limit is scale. One or two subjects hold well. Crowds and busy ensembles still drift, so the feature is strongest on focused shots rather than packed ones.
Prompt adherence is quieter than audio or camera work, and it may be the most practical strength of all. When a model renders close to what you asked for, you regenerate less, and regenerating is where time and money go. Testers reported that Seedance follows detailed prompts more closely than most of its peers, which is a large part of why professionals took it seriously rather than treating it as a toy.
The payoff is concrete. Ask for a specific action, a specific lens, a specific mood and a time of day, and a model that honours all of it saves the four or five regenerations a looser system would demand.
None of this happened in a vacuum. Seedance comes from ByteDance, the company that runs TikTok and CapCut, which brings two advantages most AI startups lack. It has enormous research scale, and it has a distribution path straight into the apps where short video already lives. A model launching with that behind it earns attention on the name alone.
The distribution point is easy to underrate. ByteDance can place a new model in front of the billions of short-video users already inside TikTok and CapCut, which turns a research release into a mass product overnight. No independent lab starts with that reach.
There is one more reason it went viral, and it is the reason the story took a turn.
Early users generated startlingly real clips of famous actors and film characters, and those clips spread far beyond the AI crowd. That realism proved the model was in the same class as the best Western systems. It also created a problem that capability alone cannot explain, which is where the second half of this story starts.
A model trending on hyper-real celebrity clips is a model borrowing faces it does not own. The rights holders noticed. Industry coverage reported that in mid-March 2026, about a month after launch, cease-and-desist letters arrived from Disney, Paramount, Warner Bros. and the Motion Picture Association over the use of their characters and likenesses.
ByteDance responded by pausing the global rollout.
The effect was immediate. Access retreated toward ByteDance's home market, leaving much of the world waiting or locked out. To cut its legal exposure the company also tightened the model itself. Uploading a real human face as a reference became blocked, including custom AI faces that never existed. Features that attached a specific voice to a specific face were switched off on the main platforms. The exact trick that made Seedance famous became the thing it would no longer do.
A paused launch and a self-imposed muzzle would keep any product in the headlines. Seedance got a third act on top.
In early April a model called HappyHorse-1.0 appeared on the same leaderboard, overtook Seedance in the categories without sound, then went quiet, with Alibaba later named as the source and its public access still unclear. Around the same window OpenAI's Sora, one of the names Seedance had been measured against, shut down for good. The leaderboard itself became a story, reshuffling in public while its biggest brands paused, vanished, fell or simply went silent.
The legal hit carries weight beyond one product. Seedance is the first model of this quality to be pulled back this hard by the people whose characters it reproduced. That makes it a test case. Every rival watched a top model trend, then retreat, and drew the obvious lesson about where the line now sits.
Put the two halves together and the volume makes sense. A strong model would have earned respect. This run of events earned headlines. Capability got it noticed by professionals, and the drama got it noticed by everyone else.

Feature lists blur together, so here is the shape of the difference in one view. The older-model column describes where video generation sat before this wave, not any single competitor.
| Feature | Older models | Seedance 2.0 |
|---|---|---|
| Motion | Stiff, prone to warping in fast action | Fluid, with occasional distortion in quick motion |
| Camera | Fixed or crude moves | Described pans and orbits, coarse on fine pacing |
| Audio | Added in a separate step | Generated with the video in one pass |
| Prompt following | Loose, heavy on retries | Close adherence to detailed prompts |
| Storytelling | One shot at a time | Multiple shots with a consistent character |
| Resolution | Often capped low | 720p base, up to 1080p and 2K on higher tiers |
| Character consistency | Drifts across frames | Holds across a scene, within limits |
The pattern in that table is the story in miniature. Seedance did not win by pushing one number higher. It closed several gaps at once, so the everyday friction of AI video, the retries, the silent clips, the drifting characters and the stiff motion, dropped in a single release. That is a harder thing to do than topping one metric, and it is why the reaction was louder than a normal version bump.
My read, claim by claim. I have kept these to direct calls rather than fence-sitting.
| The claim | My assessment |
|---|---|
| Best AI video model | First in the audio categories, already passed in some no-audio ones. A leader, in a race that keeps moving. |
| Hollywood quality | The best clips look filmed. The median clip needs retries and cleanup. |
| Director-level control | Strong control over references. Coarse control over pacing and camera. |
| Instant production-ready video | Fine for short social and ad drafts. Not yet reliable for long-form delivery. |
| Available to everyone | Gated across much of the world after the rollout pause. |
Read together, the assessments point one way. The capability side of the hype mostly holds, and the availability side does not. A model can be the best in its category and still be the wrong choice for a given project, and Seedance sits exactly on that split.
Fit varies more than the demos suggest. The same model that saves one team hours costs another team time, depending on how finished the output has to be. Here is where the return is clearest:
The common thread is short-form and draft-stage work, where speed beats polish. Anyone needing finished and reliable long-form output is not the target yet. The tool rewards teams that treat it as a fast first pass and keep a human in the edit, and it frustrates anyone expecting a finished film to fall out of one prompt.
The demos are curated. Real use brings limits worth naming before anyone commits a workflow to it. None of these is fatal on its own, but together they decide whether Seedance fits a real pipeline or stays a place to experiment:
Seedance 2.0 is a snapshot of where the whole field is heading, which is why the attention outlasts the individual model. The direction is clear on a few fronts. Clip length will stretch past the current fifteen-second ceiling. Audio will improve in more languages, not only English. Editing and reference control will keep moving toward something closer to directing than prompting.
The harder shift is not technical. The studio pushback that paused this rollout is the opening round of a fight over training data and likeness rights that every serious video model will face. How that resolves will shape which tools reach a global audience and which stay walled inside one market. Capability is no longer the only bottleneck. Permission is becoming one too.
Enterprise adoption will follow the same fault line. Large teams want the output quality, and they need stability and clear rights before they build a pipeline on any model. The vendors that pair strong generation with a settled legal footing will win the accounts, whatever the leaderboard says on a given week. Interactive and real-time video sit further out, but the pull toward them already shows in how these tools get used for rapid drafts.
That is the real reason to watch Seedance 2.0. It is the first model to make winning the benchmark and winning the right to ship look like two different problems.

Microsoft plans to cut thousands of jobs next week across sales, consu...

Wix-owned Base44 launches Base1, its own AI model for vibe coding, bet...

Thinking about Brasssmile? Read our honest review covering content qua...

Ford rehired veteran 'greybeard' engineers after AI-powered quality in...

OpenAI launched GPT-5.6 on Friday, but a White House approval list - n...

Patronus AI raised $50M to expand its simulated "world models" that st...
Discussion